摘要:設計了一個嵌入式語音識別系統(tǒng),該系統(tǒng)硬件平臺以ADSP-BF531為核心,采用離散隱馬爾可夫模型(DHMM)檢測和識別算法完成了對非特定人的孤立詞語音識別。試驗結果表明,該系統(tǒng)對非特定人短詞匯的綜合識別率在90%以上。該系統(tǒng)具有小型、高速、可靠以及擴展性好等特點;可應用于許多特定場合,有很好的市場前景。文中講述了該系統(tǒng)CODEC、片外RAM、ROM以及CPLD等與DSP的接口設計,語音識別運用的矢量量化、Mel倒譜參數(shù)、Viterbi等有關算法及其實際應用效果。
關鍵詞:ADSP-BF531;語音識別;離散隱馬爾可夫模型;非特定人;孤立詞
自上世紀70年代以來,國內(nèi)外的專家們在語音識別研究領域內(nèi)取得了重大突破,先后出現(xiàn)了動態(tài)時間規(guī)整技術(DTW)、隱馬爾可夫模型(HMM)和人工神經(jīng)網(wǎng)絡(ANN)等3種主要方法。DTW雖然在孤立詞語音識別中取得了不錯的性能,但其要求的存儲量和計算量太大;ANN雖然前景看好但其目前尚未有突破性進展,目前它們都難以在工程中得到廣泛的應用。HMM算法使語音識別的計算量得到大大減少,而且正確率較高,從而在語音識別中得到廣泛引用。
筆者在以ADSP-BF531為核心構建的嵌入式系統(tǒng)上實現(xiàn)了對非特定人、孤立詞的語音識別,該系統(tǒng)采用了端點檢測、矢量量化(VQ)和離散隱馬爾可夫模型(DHMM)等算法。
1 ADSP-BF531介紹
ADSP-BF531是ADI公司Blackfin系列的高性能DSP,其最高主頻為400MHz,內(nèi)有2個16位MAC,2個40位ALU,4個8位視頻ALU,以及1個40位移位器,RISC式寄存器和指令模型,編程簡單,編譯環(huán)境友好。
BF531包含豐富的外設,通用外設如UART、帶有PWM(脈沖寬度調(diào)制)和脈沖測量能力的定時器、通用的I/O標志引腳、以及一個實時時鐘和一個“看門狗”定時器。它還有多個獨立的DMA控制器,能夠以最小的處理器內(nèi)核開銷完成自動的數(shù)據(jù)傳輸。DMA傳輸可以發(fā)生在ADSP-BF531處理器的內(nèi)部存儲器和任何有DMA能力的外設之間。此外,DMA傳輸也可以在任何有DMA能力的外設和已連接到外部存儲器接口的外部設備之間完成(包括SDRAM控制器、異步存儲器控制器)。具有DMA傳輸能力的外設包括SPORTS、SPI端口、UART和PPI端口。每個獨立的有DMA能力的外設至少有一個專用DMA通道。
2 硬件電路設計
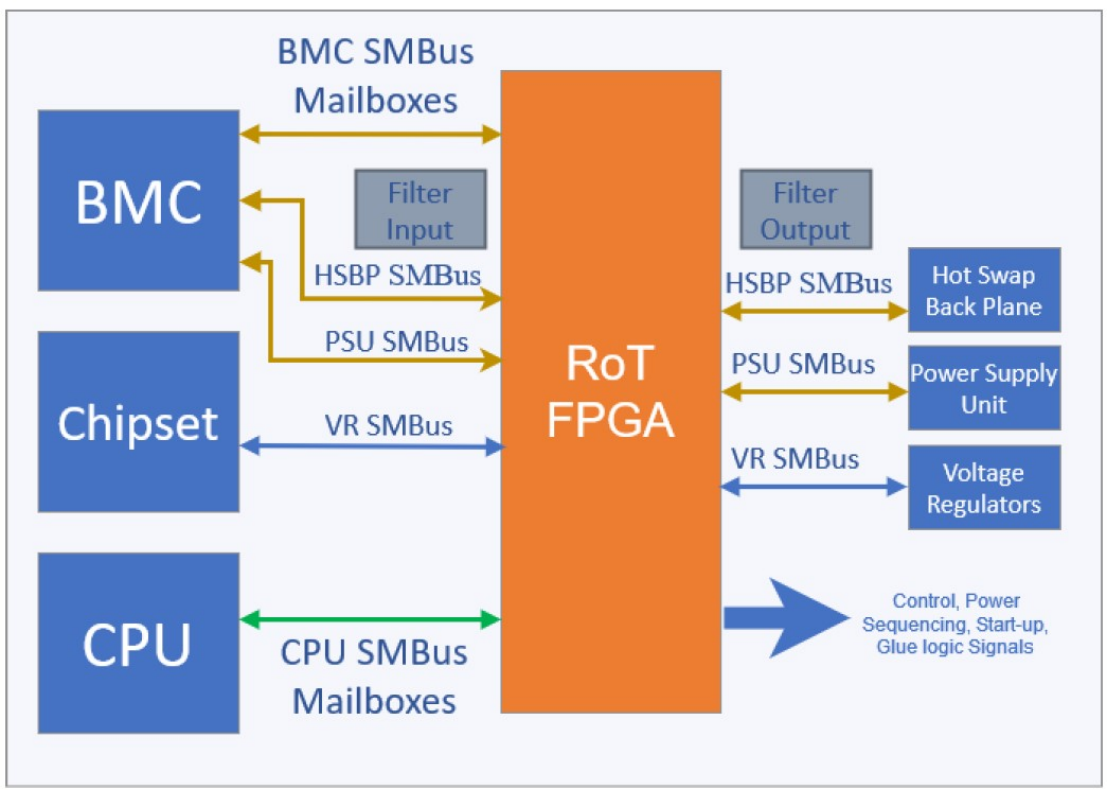
該系統(tǒng)電路主要由DSP、音頻編碼器、CPLD、片外SDRAM、FLASH和EEPROM存儲器以及電源、時鐘等組成。硬件接口如圖1所示。
各器件的主要功能如下:
1)AD73311將經(jīng)前置放大后的麥克風音頻信號經(jīng)A/D轉換后通過串行端口輸入BF531,同時完成對BF531輸出的數(shù)字音頻信號的D/A轉換,而后輸出到功放和喇叭;
2)BF531作為該系統(tǒng)的核心,對信號進行特征提取和DHMM識別,同時對其外圍的器件進行控制管理;
3)CPLD完成對DSP的外圍的器件時序和數(shù)據(jù)流程控制,以及對LCD顯示屏初始化檢測設置;
4)由于DSP片內(nèi)的RAM有限,配置了一塊SDRAM用于擴展系統(tǒng)的內(nèi)存,以滿足程序運行時數(shù)據(jù)和指令存儲的要求;
5)EEPROM用于存放DSP程序代碼和系統(tǒng)初始化所需的數(shù)據(jù);
6)FLASH用于存放訓練樣本庫。
2.1 AD73311與BF531接口設計
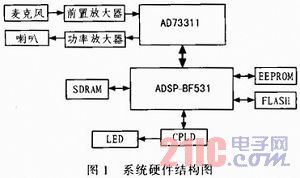
本系統(tǒng)中設計AD73311的采樣率為16 kHz,其與BF531的串口0(SPORT0)連接,通過DMA方式在單時鐘周期內(nèi)完成操作。BF531支持32 bit的串口數(shù)據(jù)傳輸,由于AD73311為16 bit的音頻器件,而且16 bit已可滿足系統(tǒng)精度要求,因此本系統(tǒng)只使用了BF531的主傳輸數(shù)據(jù)通道,即:DTOPRI和DROPRI,而將第二傳輸數(shù)據(jù)通道DTOSEC和DROSEC進行了屏蔽。AD73311與BF531的連接方式如圖2所示。
2.2 SDRAM接口設計
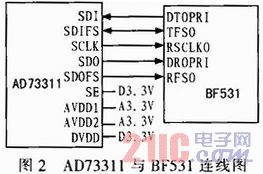
SDRAM主要用于擴展系統(tǒng)內(nèi)存,為保證程序運行的裕量及后續(xù)升級的需要,這里選用了三星電子的一款容量為32 MB的移動式SDRAM,其型號為K4M56163PG。SDRAM與DSP的I/O總線連接,如圖3所示。
2.3 EEPROM接口設計
EEPROM主要用于存放程序代碼,選用ATMEL公司的AT45DB161D-TU型的EEPROM,該型存儲器采用SPI接口,容量為2 MB,可以滿足程序存儲的要求,其與DSP的SPI端口連接。
通過設置EEPROM存儲器的SPI主模式啟動(即設置BMODE=11),現(xiàn)實配置BF531為連接一個SPI存儲器的主設備和存儲器的加載。為了正常工作,該加載模式需要在MISO加上拉電阻。否則,BF531將從MISO引腳讀取到0xFF(即SPI存儲器沒有寫任何數(shù)據(jù)到MISO引腳)。不僅MISO線上的上拉電阻是必要的,額外的上、下拉電阻還有如下2個用途:
1)上拉PF2信號,確保SPI存儲器存DSP復位狀態(tài)下未激活;
2)在SPICLK上用下拉電阻,使顯示畫圖更加清晰。
2.4 FLASH接口設計
片外FLASH主要用于存訓練樣本庫,本系統(tǒng)采用的NANDFLASH為三星電子的K9F8G08U0M-PIB0,該FLASH為工業(yè)級SLC架構(Single Laver Cell,單層單元)芯片,具有速度快、可靠性高等特點,而且容量為1 GB,可以滿足存儲大量樣本數(shù)據(jù)的要求。其采用EBIU(External Bus Interface Unit,外部數(shù)據(jù)總線)和單個GPIO(General Purpose Input Output,通用輸入/輸出引腳實現(xiàn)與DSP數(shù)據(jù)通訊。
3 軟件設計
3.1 語音識別(孤立詞)的原理
本系統(tǒng)采用的孤立詞語音識別的原理框圖如圖4所示。
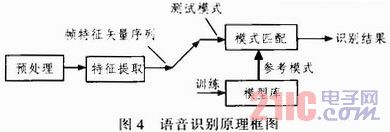
1)預處理 對聲源信號進行抗混疊濾波、A/D轉換、預加重及端點檢測等內(nèi)容,以獲得比較理想的處理信息對象。
2)特征提取 從語音波形中提取出隨時間變化的能夠反映原始語音特征的矢量序列。
3)語音訓練 建立聲學模型,將獲取的語音特征通過必要學習算法產(chǎn)生。
4)模式匹配 在識別時將輸入的語音特征同聲學模型進行比較,得到識別結果。
在訓練階段,用戶將詞匯表中的詞依次讀一遍,并且將其特征矢量序列存入模板庫中。在識別階段,將輸入語音的特征矢量序列依次與模板庫中的每一個模板進行形似度比較,相似度最高者作為識別結果輸出。
在HHM算法中,語音序列被看做馬爾可夫隨機過程的輸出。假定識別系統(tǒng)的詞匯表共包括V個詞條,那么在訓練階段需要請很多個說話人分別將這次詞條說一遍并存入數(shù)據(jù)庫中。利用這些訓練數(shù)據(jù)可以為每一個詞條建立一套HMM參數(shù)λv(1≤v≤V)。
在識別時,對于每個待識別語音,可以得到一個觀察矢量序列Y=[y1,y2,…yN],其中,N為輸入語音所包含的幀數(shù)。語音識別的過程就是計算每個HMM模型λv產(chǎn)生Y的概率P(Y|λv),并使得該概率達到最大的HMM模型,那么該模型所對應的詞條即為孤立詞識別的結果,即:
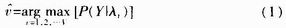
3.2 語音識別算法設計
本系統(tǒng)采用VO/DHMM(矢量量化/離散隱馬爾可夫模型)算法,其主要包括預處理、特征提取、語音訓練、模式匹配等幾個方面。
3.2.1 預處理和特征提取
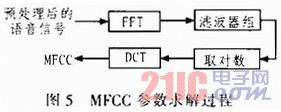
首先采用預加重、漢明窗、雙門限法等完成對語音信號的預處理;然后使用Mel倒譜參數(shù)(MFCC)進行特征識別,MFCC參數(shù)提取的過程如圖5所示,其中Mel濾波器組的作用是利用人耳聽覺特性對語音信號的幅度平方譜進行平滑。對數(shù)操作的用途:壓縮語音譜的動態(tài)范圍;考慮乘性噪聲,將頻域中的乘性成分轉換成加性成分。離散余弦變化主要是用來對不同頻段的頻譜成份進行解相關處理,使得各維向量之間相互獨立。
3.2.2 矢量量化
矢量量化(VQ,Vector Quantization)是一種重要的信號壓縮方法,其過程是:將語音信號波形的K個樣點的每一幀,或在K個參數(shù)的每一參數(shù)幀,構成K維空間中的一個矢量,然后對矢量進行量化。量化時,將K維無限空間劃分為M個區(qū)域邊界,然后將輸入矢量與這些邊界進行比較,并被量化為“距離”最小的區(qū)域邊界的中心矢量值。
一個VO編碼器往往擁有一個或多個由具有代表意義的矢量組成的集合,稱為“碼本”(本系統(tǒng)中碼本大小為256),其中每個矢量稱為“碼矢量”。在語音識別中,訓練用的語音特征通過聚類的方法形成碼書;識別時,VO編碼器將待識別語音的特征矢量與碼書中的每個矢量進行失真測度運算,最小的失真測度所對應的碼字的標號代替輸入矢量。
3.2.3 HMM模型建立及訓練過程
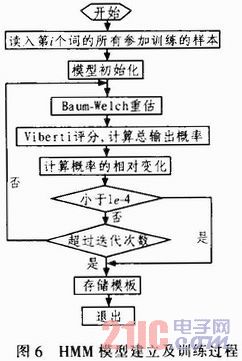
本系統(tǒng)選擇尤跨越的從左向有的HMM模型,狀態(tài)數(shù)取6。訓練過程中利用Baum-Welch算法和Viterbi算法來計算所有觀察序列的輸出概率,然后對其進行累加,得到總輸出慨率,采用前后2次的輸出概率的相對變化小于一定閾值(如:1×10-4)或超過迭代次數(shù)作為訓練結束的判據(jù)。程序流程圖如圖6所示。
3.2.4 語音識別
語音識別的過程即是用Viterbi算法將經(jīng)將輸入的矢量量化后的語音與模型庫中的參考模板進行匹配。
Viterbi算法是一種前向搜索算法,其可以是在給定相應的觀察序列時,找出從模型λ中找出的最佳狀態(tài)序列,即選擇輸出概率最大的模版作為輸出結果。對數(shù)形式的Viterbi算法,能夠避免大量的乘法運算,減少計算量,同時還可以保證有很高的動態(tài)范圍,不會出現(xiàn)由于過多的連乘而導致溢出問題,其算法如下:

4 實驗結果及分析
系統(tǒng)選取500字的詞表,詞長不大于5;在進行識別前,對每個待識別的詞進行訓練,參加訓練人數(shù)為30,其中男性20人,女性10人。實驗選取30個人,其中參加訓練和未參加訓練的各15人,對簡單語音命令、數(shù)字串、字母串進行測試(每人反復測試5次),結果如表1所示。
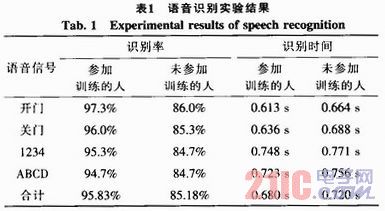
通過以上數(shù)據(jù)可以看出,該系統(tǒng)的對非特定人(包括參加訓練和未參加訓練)的簡單漢語詞匯、數(shù)字串、字母串等的綜合識別率超過了90%,識別時間在0.7 s左右;具有較高的識別率和較好的實時性。從表中可以看出,未參加訓練與參加訓練的識別率相差約10%,可以通過在軟件中增加訓練樣本量以及完善有關算法等來進一步提高其識別率。
5 結束語
該嵌入式語音識別系統(tǒng)在以ADSP-BF531為核心的硬件基礎上,成功運用DHMM算法完成了對非特定人孤立詞的語音識別。該系統(tǒng)運行穩(wěn)定、可靠,其識別率及實時性均滿足使用要求,同時還具有存儲容量大、運算速度快的特點,為軟件運行留下了充足的裕量,系統(tǒng)后續(xù)的完善和升級較容易實現(xiàn)。該系統(tǒng)可應用于許多特定場合,有很好的市場前景。
聲明:本內(nèi)容為作者獨立觀點,不代表電源網(wǎng)。本網(wǎng)站原創(chuàng)內(nèi)容,如需轉載,請注明出處;本網(wǎng)站轉載的內(nèi)容(文章、圖片、視頻)等資料版權歸原作者所有。如我們采用了您不宜公開的文章或圖片,未能及時和您確認,避免給雙方造成不必要的經(jīng)濟損失,請電郵聯(lián)系我們,以便迅速采取適當處理措施;歡迎投稿,郵箱∶editor@netbroad.com。